sphenix-tracking-l AT lists.bnl.gov
Subject: sPHENIX tracking discussion
List archive
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?
- From: Christof Roland <christof.roland AT cern.ch>
- To: Haiwang Yu <yuhw.pku AT gmail.com>
- Cc: "sphenix-tracking-l AT lists.bnl.gov" <sphenix-tracking-l AT lists.bnl.gov>
- Subject: Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?
- Date: Mon, 3 Jul 2017 23:16:46 +0200
Hi Haiwang,
pions show pretty much the same thing. See below.
Christof
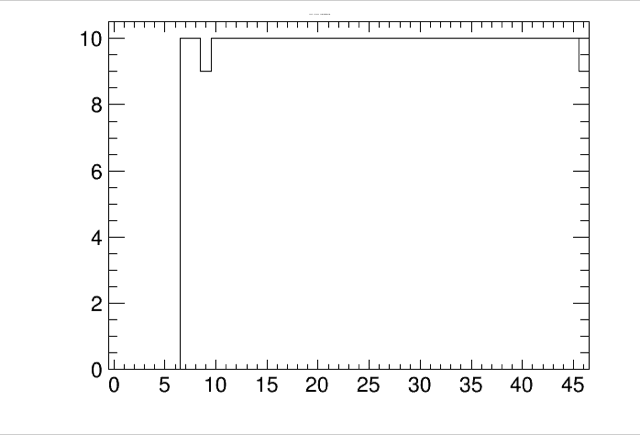
On 3. Jul 2017, at 22:53, Haiwang Yu <yuhw.pku AT gmail.com> wrote:Hi Christof,
What about pions?Haiwang<hitsperlayer.gif>On Mon, Jul 3, 2017 at 16:40 Christof Roland <christof.roland AT cern.ch> wrote:Hi All,Haiwang is right, you have to turn off the scan_embed switch to get all clusters.To speed things up for Hijing and get at least ntuples for all reco objectsyou can turn the matching off by setting eval->do_track_match(false).To get the number of clusters per layer just plot:ntp_cluster->Draw("layer>>h(47,-0.5,46.5)","event==1&&layer>6")In my standard 10 muon events I do not see excess clusters with the latestversion of the setup macro.See attached plot.CheersChristofOn 3. Jul 2017, at 20:23, Haiwang Yu <yuhw.pku AT gmail.com> wrote:Hi Tony,If you turn off the scan_embed switch in the SvtxEvaluator, the evaluator will output all clusters.It takes a very long time to do that for Hijing. For this issue, I would think running single pions would be enough to see the nclusters/layer.Cheers,HaiwangOn Mon, Jul 3, 2017 at 12:14 PM Anthony Frawley <afrawley AT fsu.edu> wrote:Hello Christof and Sourav,
Sookhyun is working on track seeding, so she was looking at all clusters, not clusters associated with tracks. Not sure how to see that from the evaluator ntuples ....
Tony
From: sourav Tarafdar <sourav.pheonix AT gmail.com>
Sent: Monday, July 3, 2017 11:53 AM
To: Christof Roland
Cc: Anthony Frawley; sphenix-tracking-l AT lists.bnl.gov
Subject: Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?_______________________________________________Hi Christof and Tony,
Since yesterday I already did three iterations of Hijing embedded 100 muons per event. I didn’t really face any memory related issue. I submitted 1000 condor jobs in each iterations with 2 Hijing events per job. I have been registering only embedded muons. The phase space of the muons are 1. < pT < 50 GeV, 2 units of eta , and 2*pi in phi.
So far I also didn’t notice the issue in clustering pointed by Sookhyun. I see about 0.94 clusters per true track-layer in pure muon events where muons have the same phase space as quoted by me for Hijing embedded muons.
Best regards,-Sourav
On Jul 3, 2017, at 10:31 AM, Christof Roland <christof.roland AT cern.ch> wrote:
Hi Tony,_______________________________________________
thanks a lot for your response. Good to see that some events actually do finish.I'll try a diffent test event ans see if I get some result there.
I am not sure I can reproduce the clustering problem.With the current setup I get about 0.94 hits per particle-layer crossingfor muon events. Did Sookhyun run the latest greatest macro?
Cheers
Christof
On 3. Jul 2017, at 17:07, Anthony Frawley <afrawley AT fsu.edu> wrote:
Hi Christof,
Over the weekend I have been running 2000 jobs at a time with central Hijing+ 100 pions + 1 upsilon. About 1400-1500 of them do not reach the 20 GB limit and finish within ~ 1.5 hours. Of the rest, some crash (~50), ~250 are put on hold when they get too big, and ~ 200 are running but are just taking too long. So after ~ 1500 jobs finish I "condor_rm" the rest and start another 2000.
It is not very satisfactory, but I need to get these done so I can make performance plots that are needed now. We need to solve the clustering issue pointed out by Sookhyun, since that is likely the problem.
Tony
From: sPHENIX-tracking-l <sphenix-tracking-l-bounces AT lists.bnl.gov> on behalf of Christof Roland <christof.roland AT cern.ch>
Sent: Monday, July 3, 2017 10:25 AM
To: sphenix-tracking-l AT lists.bnl.gov
Subject: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?Hi Everybody,
even with the more recent change to the TPC macro I am still having trouble running Hijing events.
The jobs blow up to 20GB and then just hang. These are jobs that just do run simulation up to cluster
level and then write to disk.
Did anyone mange to run any hijing events to the end lately?
Also in the log file root throws an error:
Error in <TBufferFile::WriteByteCount>: bytecount too large (more than 1073741822)
Has anyone seen these?
Thanks for your input
Christof
_______________________________________________
sPHENIX-tracking-l mailing list
sPHENIX-tracking-l AT lists.bnl.gov
https://lists.bnl.gov/mailman/listinfo/sphenix-tracking-l
sPHENIX-tracking-l mailing list
sPHENIX-tracking-l AT lists.bnl.gov
https://lists.bnl.gov/mailman/listinfo/sphenix-tracking-l
sPHENIX-tracking-l mailing list
sPHENIX-tracking-l AT lists.bnl.gov
https://lists.bnl.gov/mailman/listinfo/sphenix-tracking-l
-
[Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Christof Roland, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Anthony Frawley, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Christof Roland, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
sourav Tarafdar, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Anthony Frawley, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Haiwang Yu, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Christof Roland, 07/03/2017
- Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?, Haiwang Yu, 07/03/2017
- Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?, Christof Roland, 07/03/2017
- Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?, Anthony Frawley, 07/03/2017
- Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?, sookhyun lee, 07/06/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Christof Roland, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Haiwang Yu, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Anthony Frawley, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
sourav Tarafdar, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Christof Roland, 07/03/2017
- Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?, sourav Tarafdar, 07/03/2017
-
Re: [Sphenix-tracking-l] Did anyone manange to run Hijing lately?,
Anthony Frawley, 07/03/2017
Archive powered by MHonArc 2.6.24.