star-qaboard-l@lists.bnl.gov
Subject: STAR QA Board
List archive
- From: "Hu, Yu" <yuhu@bnl.gov>
- To: Eugenia Khyzhniak <eugenia.sh.el@gmail.com>
- Cc: "star-qaboard-l@lists.bnl.gov" <star-qaboard-l@lists.bnl.gov>
- Subject: Re: [STAR-QAboard] QA Board Meeting July 22
- Date: Sat, 23 Jul 2022 04:08:19 +0000
Hi Eugenia,
>The problem is: while the traditional algorithm doesn't take into account "jumps", your algorithm also failed to capture some bad runs that were clearly marked bad in the shift log. So these two algorithms are equally good/bad because neither of them can
find all the bad runs.
I think this argument is not correct, or say, not accurate. The "traditional algorithm" doesn't take care of "jumps"(global n-sigma cuts), the "isobar rbyr QA algorithm" can take the jumps into account but have a "few runs accuracy" problem, the new algorithm
we presented today is an improvement of finding jumps. Also, the so-called "bad runs", no matter found by eye or algorithm, are just "bad runs candidate", which has in-normal physics value compare with other runs. That may due to physics, may known detector
issues, or other unknown issues. But even if we cannot find it in the log, many people usually still pick it out, because we think that could due to an unknown reason. So this step is not an alternative to checking log, it is just something we think it's helpful
and a useful reference. That's why we need to run through the data, do a run-by-run QA with data, and make and see the plot, not just go run log and feel safe. And that's why we have an algorithm.
But if you are asking if you need to do this step for this particular dataset, for confirming whether one run needs to be produced or not, or for the purpose of passing a list to the centrality team. I think it's depending on you and your supervisor. But
I would suggest you do because this is simply a reference to give you more confidence in your findings.
As for about the time we spend on development is worth or not, I don't have any argument. To me, it's worth, it because the results we got from this algorithm are a good reference. It's a big improvement compared with the traditional one. Even if it's
not big, every single bit of improvement is important and useful if we can do it. We always do our best.
The small fraction of difference that got by Li-ke and Ashik, I guess, is mainly driven by the hiding cuts, statistics, and "a few runs accuracy" in the old algorithm. I think the current run will give them a better consistency if they want to run the
algorithm again with their root files. Overall, I don't think a slightly different run list is an issue, the previous algorithm was the best that what we can come up by that time, but as I said, it has some limitations, and that's why we came up with a newer
version. And also, that is not human bias, it's more close to statistics or systematics.
I would prefer to think in another way, the current version is just an improvement on the old-fashion method, same as many improvements of analysis methods, a small step. Not for finding the shift log bad run, but for finding the outlier candidates. A
different list of bad runs got by different version doesn't mean the previous results is wrong, it is our new/latest understanding.
Just like the link you shared, that are the variables people think are important. I think that's where/when people need this kind of algorithm most.
Overall, thanks for your comments and suggestions. I later realized my previous email might be too emotional in terms of tones. Please forgive me if you think the tone is too strong or uncomfortable. I'm not on purpose and I should be more scientific.
I apologize to you and to everyone for sending that email with that tone. I will learn next time.
Thank you.
Best,
Yu
From: Eugenia Khyzhniak <eugenia.sh.el@gmail.com>
Sent: Friday, July 22, 2022 22:58
To: Hu, Yu <yuhu@bnl.gov>
Cc: Ting Lin <tinglin@sdu.edu.cn>; star-qaboard-l@lists.bnl.gov <star-qaboard-l@lists.bnl.gov>; cebra <cebra@physics.ucdavis.edu>
Subject: Re: Re: [STAR-QAboard] QA Board Meeting July 22
Sent: Friday, July 22, 2022 22:58
To: Hu, Yu <yuhu@bnl.gov>
Cc: Ting Lin <tinglin@sdu.edu.cn>; star-qaboard-l@lists.bnl.gov <star-qaboard-l@lists.bnl.gov>; cebra <cebra@physics.ucdavis.edu>
Subject: Re: Re: [STAR-QAboard] QA Board Meeting July 22
Hi Yu,
> Today you asked if one automated algorithm can not give you exactly the runs marked as bad by the shifters, then why do we go this complicated.
I believe there is some misunderstanding. It wasn't a question of why the algorithm was needed at all.
I will try to clarify what I wanted to say.
I understand the importance of the r-b-r QA algorithm.
The problem is: while the traditional algorithm doesn't take into account "jumps", your algorithm also failed to capture some bad runs that were clearly marked bad in the shift log. So these two algorithms are equally good/bad
because neither of them can find all the bad runs.
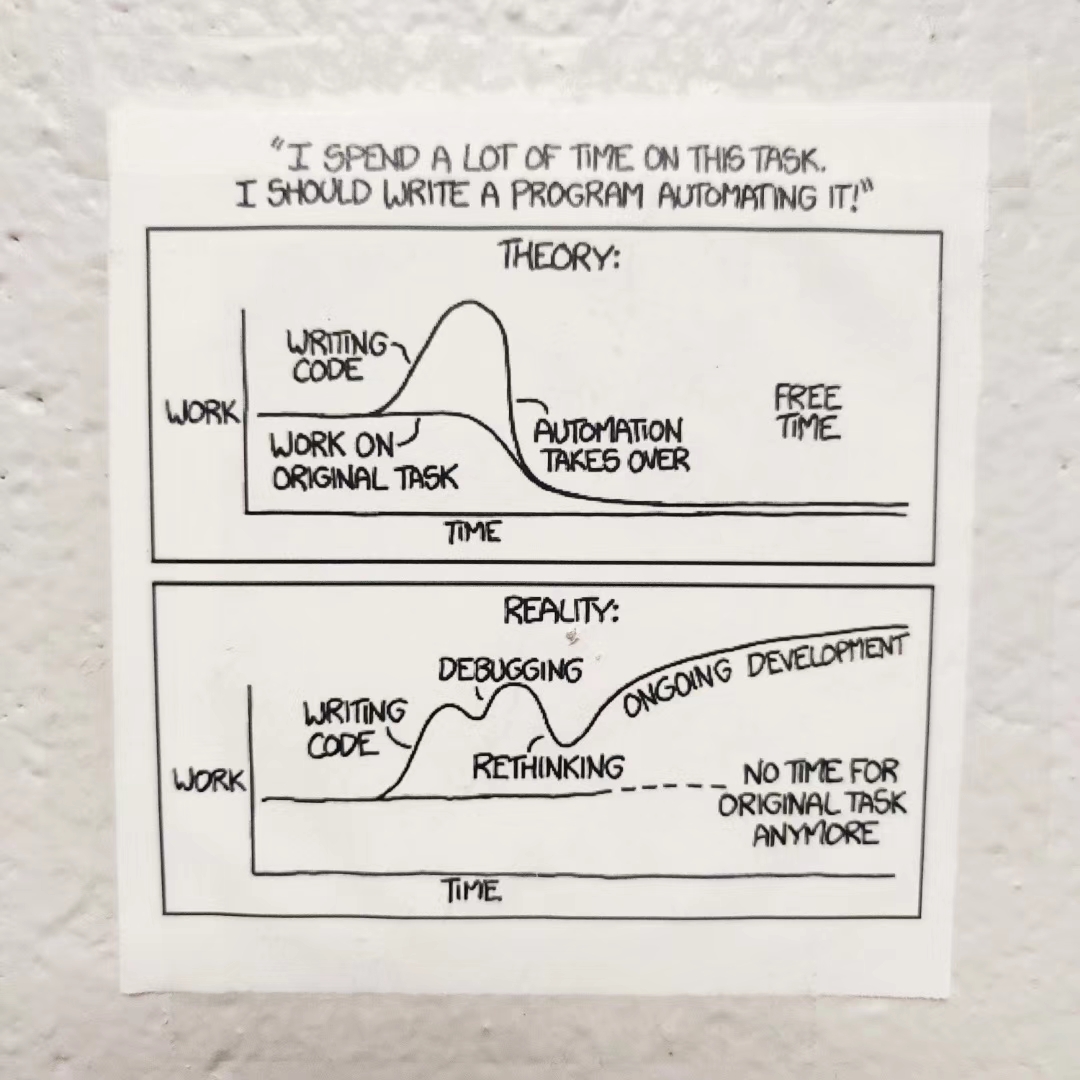
I agree that the idea of having an automatic algorithm that eliminates human judgment is an abstractly good one. But the reality is the same as in your picture.
It's just not worth the hassle for several months now. That is, what could be done slowly in a month by hand for all data sets turned into an algorithm development that has been going on for half a year (or more). An exorbitant
amount of human effort is spent for an algorithm that will perform, on average, the same as the simplest one written in a day (for example Ashik and LiKe 's results are still different - it will always be a human factor and some bais. Maybe it will be also
good to add some parser for events which was considered for the QA). In any case, even the choice of variables for analysis is slightly subjective. For example, some group can work with EPD (for example, here are a bunch of "important" variables for different
groups
https://drupal.star.bnl.gov/STAR/pwg/common/bes-ii-run-qa) , but we do not consider these variables at all. One way or another, they will remove bad runs by hand or will not do it at all - that is, it is impossible to get rid of the human factor, no matter
how advanced this algorithm is.
Again, I'm not against the algorithm, it's just a comment about a general idea.
> A naive thought is a webspider&AI to read shift log and analysis would be very helpful, if you are interested, maybe we can discuss it a little bit more.
As I tried to say at the meeting, it makes sense if so much time has already been spent on this algorithm :) And depends on the chosen way it could be interesting to do.
> Once you said you don't care which algorithm is used because in any way it takes only a few minutes, I'm frustrated but also happy, which means our package works well.
When I say that I don't care I mean that all algorithms will take a few minutes to run, even if you want to run them all.
So, summarizing my speech I have two suggestions:
1) Add to algorithm parsing of runLog browser to be sure that there are no junk runs in the dataset.
2) Create/Fix codes which provide histograms for rbyr QA (everyone should use the same codes).
P.S. Daniel, could you please, send me information about triggers and datasets.
Best,
Eugenia
On Fri, Jul 22, 2022 at 2:03 PM Hu, Yu <yuhu@bnl.gov> wrote:
Hi Eugenia,
Today you asked if one automated algorithm can not give you exactly the runs marked as bad by the shifters, then why do we go this complicated. I'm very frustrated but not because of a question about whether an algorithm is needed or not(of course it's needed), but because right now we don't have a package that can do such work you mentioned, so people have to spend a lot of their time to do it by hand. A naive thought is a webspider&AI to read shift log and analysis would be very helpful, if you are interested, maybe we can discuss it a little bit more.
A few things I want to share with you about why we need to do the run-by-run QA and why we want to do it in this way. Looks like you have some confusion.
Based on my understanding, first of all, going to the shift log and finding which run is "bad" in person is one of the steps(also the most important step). It will help you find during the running what effort has been done by the experts and what happens to the detector. But this work will be very challenging when you have a big data set like hundreds or thousands of runs. And also, the information on the log might be a delayed response like the shift leader notices an issue that may already happened for a while. Then to track from which run it happened, and then mark rather it's really bad is even more challenging.Another possible issue is some runs are marked as bad for one of the subsystems, but that doesn't mean people, who don't use that subsystem in their analysis, cannot use that run. If one can have a detector good/problem checklist for each run that would be very good, but it is also not very easy when you have hundreds of runs.
That's why people start to look into the physics variables and then check the outliers. So they can find the outliers first, marked as bad run candidates, and then go to the shift log to check these few runs if they are really "bad". This will save a lot of time for the analyzers and speed up their analysis flow. An extra benefit we got from this is the unnormal behavior of the variable can also tell us to pay more attention to check the possible issues. Previously people use 5-RMS over all the runs and find the outliers. But that would be an issue if there is a significant change, like detectors gains, you will end up with many stable "steps", which may bring more complicated. That's why we develop this algorithm and also what this algorithm can only do. I remember when I start to do my first analysis, to get more statistics, we need to separate which small clusters by eye and then find rather there is a reason in the shift log, which is very painful.You may know the original algorithm was developed for the isobar blind analysis, but it was already finished and served well. We pushed this algorithm forward, tried to improve it, and wanted to share it with the group are just want people who start their new data, and news analysis, can do it faster and have less pain. Once you said you don't care which algorithm is used because in any way it takes only a few minutes, I'm frustrated but also happy, which means our package works well. But it's also welcome to run people's own algorithms or criteria whichever do a similar thing.I hope this can partly explain what we are doing and reply to your confusion. Share one cartoon I found from STAR control room, I think that is exactly what we are doing, what we are facing now, but we will continue to contribute.
Thank you.Best,Yu
From: Ting Lin <tinglin@sdu.edu.cn>
Sent: Friday, July 22, 2022 8:24
To: Hu, Yu <yuhu@bnl.gov>
Cc: star-qaboard-l@lists.bnl.gov <star-qaboard-l@lists.bnl.gov>
Subject: Re: Re: [STAR-QAboard] QA Board Meeting July 22Hi Yu:
Thanks, I have added into the agenda.
Best,
Ting
-----Original Messages-----
From:"Hu, Yu" <yuhu@bnl.gov>
Sent Time:2022-07-22 16:10:37 (Friday)
To: "star-qaboard-l@lists.bnl.gov" <star-qaboard-l@lists.bnl.gov>, "Ting Lin" <tinglin@sdu.edu.cn>
Cc:
Subject: Re: [STAR-QAboard] QA Board Meeting July 22
Dear Ting, and All,
Please find our slides for the tutorial from the link below:
Thank you.Best,Yu
From: STAR-QAboard-l <star-qaboard-l-bounces@lists.bnl.gov> on behalf of Ting Lin via STAR-QAboard-l <star-qaboard-l@lists.bnl.gov>
Sent: Tuesday, July 19, 2022 23:06
To: star-qaboard-l@lists.bnl.gov <star-qaboard-l@lists.bnl.gov>
Subject: [STAR-QAboard] QA Board Meeting July 22Hi all:
We will have a QA board meeting on Friday at noon BNL time. As discussed last week, we will have a tutorial session for Run-by-Run QA.
If you have slides to show, please link to the meeting page (in link below) or send it to me.
https://drupal.star.bnl.gov/STAR/event/2022/07/22/QA-Board-Meeting
Join ZoomGov Meeting:
https://urldefense.com/v3/__https://bnl.zoomgov.com/j/1618435669?pwd=L3B6M3JKcjRFMVFxQTNhaEdBdkZ5UT09__;!!P4SdNyxKAPE!BqECZdWod0cgy_FRmaFufxIlmeFvORSda0LXJBs2Jc2JvjJ6xk-0fPVe4qG5YlgcBF_YUKXnAsIoTSy-9IfZM6BsSON8VAc$
Meeting ID: 161 843 5669
Passcode: 194299
All the previous agendas are listed in the page below:
https://drupal.star.bnl.gov/STAR/comp/qa/pwg-qa/run-22-qa
Thanks.
Ting
_______________________________________________
STAR-QAboard-l mailing list
STAR-QAboard-l@lists.bnl.gov
https://lists.bnl.gov/mailman/listinfo/star-qaboard-l
-
[STAR-QAboard] QA Board Meeting July 22,
Ting Lin, 07/19/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Hu, Yu, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Ting Lin, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Hu, Yu, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Eugenia Khyzhniak, 07/22/2022
- Re: [STAR-QAboard] QA Board Meeting July 22, Hu, Yu, 07/23/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Eugenia Khyzhniak, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Hu, Yu, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Ting Lin, 07/22/2022
-
Re: [STAR-QAboard] QA Board Meeting July 22,
Hu, Yu, 07/22/2022
Archive powered by MHonArc 2.6.24.